Developing High Performance Asynchronous IO Applications
Description
Written by Stas Bekman. First published Oct 12 2006 at onlamp.com (http://www.onlamp.com/).
Creating Financial Friction for Spammers
Why do spammers send billions of email messages advertising ridiculous products that most of us would never in our lives consider buying? How can someone possibly make money from this endeavor when the vast majority of spam either gets filtered out or at the very best read and discarded by a disgruntled end user?
What makes spamming profitable is huge volume. Spamming is profitable when a bait message, be it a commercial spam or a phishing email, reaches a substantial number (usually millions) of recipients. According to the New York Times, 0.02% of people click on and buy products advertised in pharmaceutical spam emails (http://www.nytimes.com/2006/07/03/technology/03drill.html). Other articles suggest that it costs about $300 to send 1 million emails, but it's possibly much cheaper to use a DIY botnet. Assuming that a spammer makes just $25 from each sale (and it can be much more than that), it's easy to see that it takes only slightly more than 2 million emails to make an immediate $10K profit. The Times article suggests that pr0n spam gets a 5.6% click rate, though the profits per click are much lower there. The spam problem exists and gets bigger by the day because it takes just a few hundred dollars to send a very large amount of emails, and the payoffs are huge.
Ken Simpson and Will Whittaker, formerly developers at ActiveState, founded MailChannels to solve the spam problem. Rather than trying to invent yet another blacklist or a content filter, they came up with a revolutionary idea. The idea was very simple: rather than trying to fight spammers by detecting spam messages and discarding them, Ken and Will decided to discourage spammers by attacking their economic raison d'etre.
By observing spammer behavior, the MailChannels team realized that spammers are impatient. If they can't deliver a message within several seconds, they tend to abort the connection and move on to spam other servers. After all, spamming is only profitable if spammers can push a lot of email across the wire. The solution used by the Traffic Control product creates that financial friction that everybody was looking for.
Nowadays, the majority of spam is sent from botnets--vast, distributed networks of compromised Windows PCs. Spammers usually rent botnets by the hour from "bot herders" (usually just a bored kid living in his parent's basement). Bot herders even make the spamming software available as a part of the botnet rental package, which makes it easy for the spammer to get to work mailing out to a large list of prospective buyers.
While botnets are vast in size and availability, the number of machines and the sending capacity of any particular botnet is limited. Furthermore, the viability of a particular bot machine decays over time, as receivers such as Hotmail and Yahoo! identify the members of the botnet and black-list them. For these reasons, it is critical for a spammer renting a botnet to get the spam out as quickly as possible to as many recipients as possible--before the bot he rented becomes blacklisted.
By slowing down email from suspicious sources (often botnets), the MailChannels team figured they could probably make the spammers give up and move on. That's exactly what happened.
Notice that I'm not talking about the commonly discussed "grey listing" technique when I use the term "slow down". Traffic Control slows down certain SMTP connections to a trickle (perhaps 5 bytes per second for both upstream and downstream). When slowed down, most spammers voluntarily abort their connection within the first 30 seconds. Legitimate users who experience accidental slowing are unaffected, because their legitimate mail servers don't mind waiting a few minutes to get an email message delivered.
While the idea is simple, the implementation is far from it. Slowed connections tend to pile up like so many cars in a traffic jam. From a traditional receiving mail server's perspective, these connections are a huge burden on memory and process resources. Add in heavy spam content filtering, email archiving, regulatory compliance monitoring, and automated message handling, and the burden of each connection increases even further. In a traditional email environment, slowing down connections is a ridiculous proposition that requires enormous server resources.
In fact, we observed that you don't even need to slow down traffic intentionally to cause loading issues. Many sites these days are barraged with torrents of spam from huge botnets, causing lengthy service outages. The high concurrency causes the damage, rather than a high throughput of messages.
Our challenge was to implement a transparent SMTP proxy what users can install in front of any existing email infrastructure to slow certain connections to a trickle, which is also incredibly scalable with respect to connection concurrency.
The First Generation
We implemented the first generation of Traffic Control using Apache and mod_perl 2 protocol handlers. We have implemented the SMTP protocol (RFC-2821) using the solid infrastructure provided by mod_perl 2. Similar to HTTP, Apache spawns a new server every time a new SMTP connection comes in (unlike HTTP, SMTP is an interactive protocol) and a custom mod_perl SMTP protocol handler takes over and communicates with the client and proxies the connection back to the MTA server (see Figure 1).
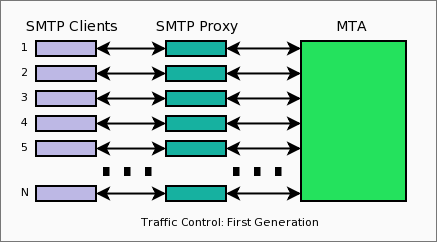
Figure 1. The first generation of
Traffic Control.
This approach worked really well with a low-traffic volume. But as soon as we put it on a production server that normally received hundreds of concurrent connections, our application couldn't deal with the load. There were two major problems. Because we held certain SMTP connections open for several minutes due to throttling, hundreds of concurrent connections turned into thousands and the machine wasn't capable of running thousands of Apache instances. The other problem was the MTA itself, as we also needed to run thousands of MTA instances each tied to a client via a transparent proxy.
This is a good example of how not to design things. If a certain technology scales well in one domain, it doesn't automatically mean that it will scale as well everywhere else.
The Second Generation
We went back to the drawing board and tried to come up with a solution that would scale well under heavy SMTP traffic. We considered the light-weight front-end, heavy-weight back-end solution familiar to mod_perl users, but it didn't work for us, because we wanted to be able to have Perl in the front end and not waste a lot of time implementing things in C. Besides, it didn't solve the second problem of having MTAs busy, which stayed idle and consumed memory most of the time.
After several brainstorming sessions, we realized that we could solve the problem by having a very light front-end process that could talk SMTP and maintain thousands of throttled and normal SMTP connections. We also realized that we need to implement SMTP multiplexing between the transparent proxy and the MTA, thus allowing a handful of MTAs handle thousands of concurrent SMTP connections, each lasting several minutes. The secret multiplexing sauce came much later, but first we needed to tackle the light-weight front-end problem.
Luckily, I've had a lot of (bad) experience with Perl threads, so it was an quick decision against even attempting to prototype a quick solution. We then hit CPAN in search of good concurrent solutions. I've had a quick fling with coroutines Perl modules (the Coro:: namespace), but not having any previous experience with those, and not being able to find someone who did, removed that option as well. That left event-based asynchronous solutions.
There were several implementations of event-loop based libraries available on CPAN, and after reviewing our options we decided to use Event::Lib (http://search.cpan.org/perldoc?Event::Lib), which provided Perl bindings around libevent. We made that choice because we needed a highly portable solution. Not only does libevent run on multiple platforms, it also supports multiple OS-level implementations on each platform (such as select(), poll(), epoll(), and kqueue).
The Event::Lib itself was well documented and had very good test coverage. Most importantly, Tassilo von Parseval, the author of the module, was extremely helpful and prompt at fixing bugs. When we started there were quite a few bugs, but Tassilo has quickly resolved most of them.
To jump forward, the second generation of Traffic Control was a major success and provides an amazing scalability thanks to Event::Lib and the multiplexing approach. The rest of this article discusses the methodology of writing applications using Event::Lib.
One Can't Afford to Block in a Single Threaded Event-based Application
Chances are that you are already familiar with interactive GUI applications, which are event-driven. Event-driven network service applications are quite different beasts. The main difference is that when a user interacts with a GUI application, she creates very few events in a short period of time (for example, clicking on a button), whereas network services normally generate hundreds of events per second (that is, handling HTTP or SMTP traffic on a busy server).
Any blocking operation in network service operation will cause a quick accumulation of pending events, causing an application slowdown and eventual non-responsiveness.
To avoid this situation, you can replace any blocking operations with their non-blocking equivalents (usually asynchronous) where possible. For example, disk and network IO operation can be made non-blocking with operating system support. Any remaining blocking or just slow operations need to be delegated elsewhere. For example, iterating over a long list of objects could significantly slow the whole application down.
If scalable threads support is available, all blocking and slow operations can run in separate threads. Unfortunately, as of this writing Perl 5's thread support is non-scalable (and often not even usable). Therefore, we needed to use some other alternative. We chose to again stick to mod_perl 2 for that purpose, by writing a very simple protocol that delegated blocking and slow operations to the pool of back-end processes.
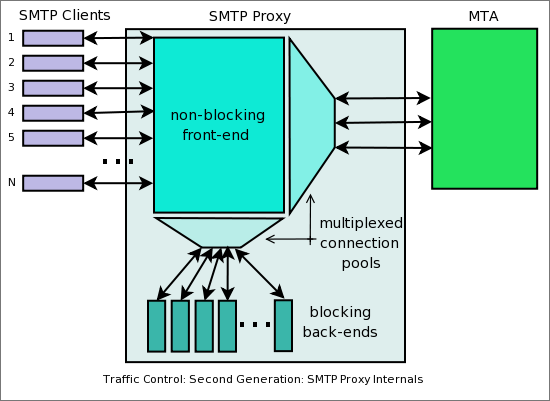
Figure 2. The second generation of
Traffic Control.
We ended up with the architecture shown in Figure 2, where there is a single threaded front-end process which performs lots of non-blocking operations (mainly network IO), and the back-end Apache/mod_perl 2 processes which deal with the slow and blocking operations. The front-end communicates with the back-end processes using a simple protocol.
The front end performs multiplexing and connection pooling to optimize the usage of the back-end and MTA resources. Connection pooling saves the overhead of pre-opening connections. Multiplexing allows multiple client connections to use a few back-end and MTA connections.
Implementing Flow Control with Event Loops
While we had experience with GUI event-based applications, that background wasn't very useful when it came to implementing flow control in our application. This is because in a typical GUI application, a user generated event (a mouse click, for example) usually either calls a blocking callback (during which the user loses the control over the application) or gets handled asynchronously (with user regaining the control immediately). Whereas in the asynchronous IO networking application, blocking is not acceptable and asynchronous operations may trigger more asynchronous operations, so implementing flow control is quite tricky.
Consider a simple task: read from a file handle and check whether a certain pattern matched the read data.
In the blocking IO synchronous flow this is easy:
my $read = sysread $rfh, my $data, 16;
die "failed to read: $!" unless defined $read;
warn "got OK\n" if $read && $data =~ /OK/;It's easy to see the sequence of operations here.
This sequence doesn't work in the async IO world, as it can't do anything that relies on the read data immediately after calling the async read operation, because asynchronous operations return before they even start. An asynchronous version of this code might be:
my $ctx = {
data => "",
len => 16,
offset => 0,
}; # context
read_then_run($rfh, \&check_OK, $ctx);
sub check_OK {
my ($ctx) = shift;
warn "got OK\n" if $ctx->{data} && $ctx->{data} =~ /OK/;
}This code encapsulates the data into a context to pass around the callbacks. The check_OK() function will executed when reading completes. Here's the read_then_run function:
sub read_then_run {
my ($rfh, $cb, $ctx) = @_;
my $read = sysread $rfh, $ctx->{data}, $ctx->{len}, $ctx->{offset};
die "failed to read: $!" unless defined $read;
$cb->($ctx);
}This is still a blocking synchronous operation.
Now assume that the $rfh file handle is non-blocking. Here's an async IO read equivalent:
sub read_then_run {
my ($rfh, $cb, $ctx) = @_;
$ctx->{cb} = $cb;
my $e = event_new($rfh, EV_READ, \&_handle_read_event, $ctx);
$e->add($timeout);
}First, this creates a read event, passing it the callback to call when the read event is triggered in the context data. Then, the code adds it to the event loop using a predefined $timeout value. The code also needs to remember what callback to call when the read operation completes, so it stashes the check_OK() function reference into the context object.
Now when someone writes to the $rfh file handle and data is available for reading, the event loop will call the _handle_read_event callback:
sub _handle_read_event {
my ($e, $e_type, $ctx) = @_;
die "timeout?" if $e_type == EV_TIMEOUT;
my $read = sysread $e->fh, $ctx->{data}, $ctx->{len}, $ctx->{offset};
# Error occurred or eof
unless ($read) {
if ($!{EAGAIN}) {
$e->add($timeout);
return;
}
else {
die "failed to read: $!";
}
}
if ($read < $ctx->{len}) { # under-read
$ctx->{len} = $ctx->{len} - $read;
$ctx->{offset} = $ctx->{offset} + $read;
$e->add($timeout);
}
elsif ($read == $ctx->{len}) {
$ctx->{cb}->($ctx);
}
else {
die "huh?";
}
}When the _handle_read_event callback is called, it first checks whether there was a timeout. The registered event handler gets triggered when there was data available to read or a timeout occurred.
If it wasn't a timeout, that means that there is data to read, so the handler attempts to read the data.
If sysread() returned undef, it indicates an error. If the system has requested a retry (with EAGAIN error), the function adds the same event to the event loop and returns. If some other error occurred, it dies.
If the read was fully successful, the very first check_OK() callback gets called, and the task is complete. If it has not read all of the requested data, the code re-adds the same event again and will continue until it has read all the data or either an error or an EOF occurs.
Similar tasks may include a readline and write operations, where the logic is pretty similar. There will be a similar async IO readline_then_run() and write_then_run() functions, which will internally handle read and write events and call the callback to run at the end of it.
When there is a callback that executes an async IO code internally, it usually returns immediately and the caller normally doesn't do anything after that, because the control must pass to that async IO handler.
Suppose you have a logical sequence of writing to a the file handle, then reading from the file handle and doing something on read completion:
write($fh, ...);
read_then_run( $fh, \&run_on_read_completed, ...);These two functions can't appear one after each in the code. Instead there should be some notion of a callback stack, where code can push items to execute and pop them off when it's time to run them. To make the previous example work you must first create a stack:
push run_on_read_completed (last to run)
push run_read
run run_writeWhen the sequence runs, it's clear that the last thing to run should be the run_on_read_completed() callback, and before it the read event should be created. Earlier the run_on_write_completed() should execute, and the very first task is to create the write event (or write directly). As each of the phases completes, the engine pops the next step from the stack and executes it, until the stack becomes empty.
The code may look like:
write_then_read($ctx, \&run_on_read_completed, ...);
sub write_then_read {
my ($ctx, $cb, ...);
push @{ $ctx->{cb} }, $cb; # pushes run_on_read_completed
run_write($ctx, \&_then_read, ...);
}
sub run_write {
my ($ctx, $cb, ...);
push @{ $ctx->{cb} }, $cb; # pushes _then_read
# create write event
my $e = event_new($ctx->{fh}, EV_WRITE, \&_handle_write_event, $ctx);
$e->add($timeout);
}
sub _handle_write_event {
my ($e, $e_type, $ctx) = @_;
# do all the async IO write logic,
# which may take more than one event
if ($writing_completed) {
my $cb = pop @{ $ctx->{cb} };
$cb->($ctx); # calls _then_read
}
}
sub _then_read {
my ($ctx);
my $e = event_new($rfh, EV_READ, \&_handle_read_event, $ctx);
$e->add($timeout);
}
sub _handle_read_event {
my ($e, $e_type, $ctx) = @_;
# do all the async IO read logic,
# which may take more than one event
if ($reading_completed) {
my $cb = pop @{ $ctx->{cb} };
$cb->($ctx); # calls run_on_read_completed
}
}This example doesn't show any read/write operations, but marks those to make it easier to see how the callbacks get passed around. Read this code in the top-down fashion because that's how it executes.
As you can see, async IO flow requires writing lots of small functions that all call each other as callbacks. Pass a context object around to maintain state.
There could be many other similar sequences that you can abstract into wrappers. With help of those wrappers, implementing more complicated logic becomes much easier.
Dying Is Not an Option
When writing async IO networking applications, you can't afford its death. When dying, the event loop will end and the application will quit. Instead, trap all exceptions and handle them gracefully without quitting the event loop. Do this by calling event_register_except_handler() before starting the event loop:
event_register_except_handler(\&event_exception_handler);
event_new(...)->add; # add the initial event(s)
event_mainloop(); # start the event loop
sub event_exception_handler {
my ($e, $exception, $e_type, @args) = @_;
# handle the exception
}$e is the event object passed to the event handler when the exception was triggered. $exception is the exception variable, either a string generated from die() or an exception object. $e_type is the type of the event (EV_READ, EV_WRITE, etc.). @args will contain the arguments passed to event_new() following the callback. If something called event_new() with:
event_new($rfh, EV_READ, \&_handle_read_event, $ctx);@args will contain the $ctx object.
In our application, an exception usually closes the file handle. We also use our own exception objects module, because we have found that all the existing exception handling systems available from CPAN, were too heavy for our needs. We found that throwing an exception object, rather than dying with a string, wasn't only more practical, it was also much faster, as in the exception handler we perform a numerical comparison, rather than matching strings.
Conclusion
Developing networking applications using event loops can be quite tricky at the beginning and requires a lot of well designed abstraction, to keep the code maintainable. Our MailChannels::AsyncConnection module that contains the abstraction went through many revisions. We hope to make it more generic and release it on CPAN once we become less busy.
We are extremely happy with the final product, because it is amazingly scalable and can handle thousands of concurrent long running connections. One of our customers recently underwent a heavy DoS attack on its mail servers, bombarding the server with thousands of requests from various botnets. Our single process non-threaded async IO application saved their systems from being brought down.
My Books

